I hope that you have F# setup (if not here’s my previous post). Type providers are a great way of loading data into your application without requiring a lot of boilerplate code and creating a lot of types at the start of project. There are many different kinds so let’s just jump right in and see what we can do.
Let’s get our type provider going, reading a csv file of bank transactions. We need some example data so let’s use this (the number of rows is not really important). Create a file named simple.csv with the following:
1
2
Type,Details,Particulars,Code,Reference,Amount,Date,ForeignCurrencyAmount,ConversionCharge
Eft-Pos,f sharp shop,1234********,1234 C,123456789123,-12.00,24/01/2016,,
We’ll just use one transaction for now to explore how these things work. Create a new Console project, Using Xamarin Studio: New Soultion -> Chosse .NET on the left -> Console Project on the right and for language select F#. You can type in any name, I’m going to use CsvHelloWorld. This will give you a souliton with a project named CsvHelloWorld with a file CsvHelloWorld.fs. Add the package FSharp.Data, and also add the csv file (simple.csv) to CsvHelloWorld project. And for the code:
1
2
3
4
5
6
7
8
9
10
11
12
13
open FSharp.Data
let [<Literal>] filename = __SOURCE_DIRECTORY__ + "/simple.csv"
type csv = CsvProvider<filename>
[<EntryPoint>]
let main args =
let data = csv.GetSample()
data.Rows |> Seq.iter (fun x -> printfn "%A" x)
0
The [<Literal>] attribute is required so the compiler can evaluate the string. This will make sense later when I describe more details about type providers. The next line creates the csv type provider reading the csv the file. GetSample() allows you to start working with the data and exploring the types, but does not load in all of the file if the file is very large. The last line is just to check that we can load the data and print it out not very useful at this stage but tests that everything is setup.
A little side note
As a side note this, I tend to name my bindings with terms from maths. This is too keep reminding me that this is not a variable but a binding (https://fsharpforfunandprofit.com/posts/let-use-do/) so in the function (fun x -> printfn "%A" x) The x is a binding and can’t be changed once assigned. Functional programming is rooted in mathematics, more specifically the lambda calculus and category theory. Don’t worry, you don’t need to get a degree in maths (though some of the extreme functionalist might suggest this). Learning names is probably the most you will need to do and this is only because the mathematicians got their first (https://vimeo.com/142347199). There are some mathematical concepts that sound hard but these are natural conclusions, like design patterns in OOP, as you build larger programs they will begin to make more sense and your programs more maintainable.
Exploring types
So the above code snippet got something going but we didn’t learn anything about the data. To explore the data pull up intellisense on the binding x:
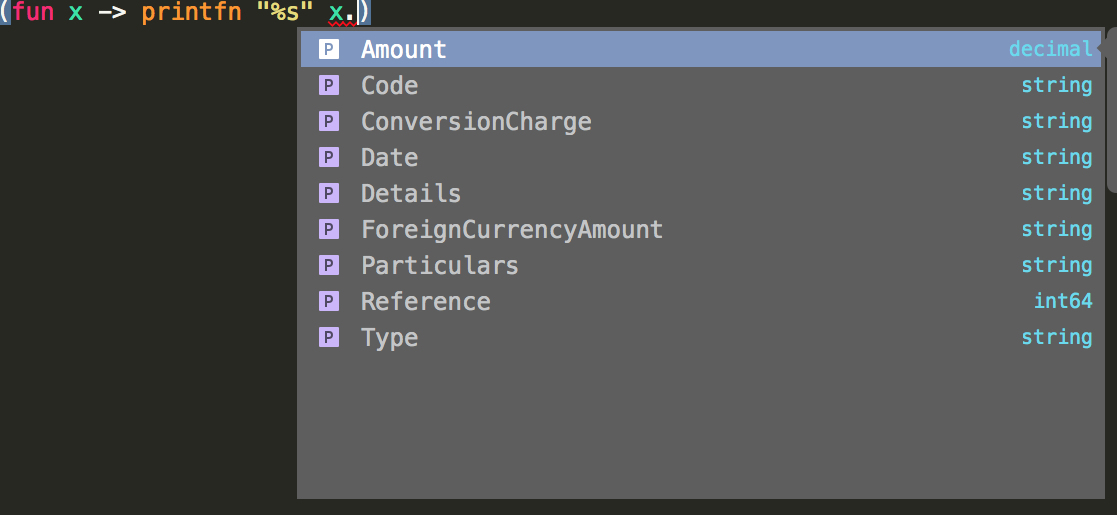
The type provider is able to find all the column names (yea I agree that’s not hard) but it has also worked out the types. Oh did I hear you say the types are just code generation under-the-hood? Sort of. Microsoft provided a white paper on how they work (https://www.infoq.com/news/2012/09/fsharp-type-providers). The very simple version is there a custom parsing layer that must be implemented and then some compiler greatness where the code generation happens dynamically, CsvProvider add the parsing layer in our case. Because the code generation happens every time you compile the solution, there is no chance of the generated code rotting. It also means the compiler only generates the types for what it needs, so will scale to a source with millions of types. Finally, because there is a customer parsing layer, many different kinds of type providers exist. There are type providers for many other data types including SQL databases, JSON, HTML, and also more extreme data sources such as the language R. Build up your data in F# and then throw it over the fence into R and the F# compiler will let you know if you did something wrong.  
A few more rows
Now that we have a little better understanding (If you’re still not getting it, press on, the code examples will help) open the csv file and add some more data:
1
2
3
4
5
Eft-Pos,f sharp shop,1234********,1234,123456789123,-12.00,12/01/2016,,1
Eft-Pos,f sharp shop,,1234 C,,42.00,24/01/2016,,
Eft-Pos,f sharp shop,1234********,1234 C,123456789123,-12.00,2/02/2016,,
Credit Card,f sharp shop,1234********,1234 C,123456789123,-12.00,24/01/2016,,
Eft-Pos,f sharp shop,1234********,1234 C,,-12.00,24/04/2016,,-3.04
To leverage the power of F# and option types we need tell the CSV type provider (update the line):
1
type csv = CsvProvider<filename, PreferOptionals=true>
Replace this:
1
data.Rows |> Seq.iter (fun x -> printfn "%A" x)
with:
1
2
let print x = printfn "%s" x
data.Rows |> Seq.iter (fun x -> Option.iter print x.Reference)
Hit the run button and should see the following:
1
2
3
123456789123
1234AB567CD9123
AB123456789123
Yay, no null pointer and no empty lines or null but how? The type provider was able to infer that the reference column had empty values and converted it to an option type. I won’t cover option types in detail (maybe in another post sometime) but they are way for the compiler to stop us from doing stupid things. Think of an option as a container that may or may not have something in it it is not possible to use the item (x.Reference binding) directly so acts like a constant message (documentation) to remind you to handle the case where it is empty In the snippet above the Option.iter is a built in function that has handles the empty case for us, so we only had to write code for the case where there is data. If you need to handle the empty case you can roll your own function as well:
1
2
3
4
5
let print x =
match x with
| None -> printfn "No reference"
| Some x -> printfn "%s" x
data.Rows |> Seq.iter (fun x -> print x.Reference)
Here we pattern match on Reference and must explicitly handle the case where there is no data. This won’t compile if you miss either the None or Some branch.  
Something possibly useful
So there were a few cool things in the above example but nothing really spectacular. Here is something that is a little more useful:
1
2
let total = data.Rows |> Seq.fold (fun sum x -> sum + x.Amount) (decimal 0)
printfn "%f" total
The following line is taking all the rows and summing the amount to give the total, all in one line. If you’re not familiar with fold, a very brief description is that is it is using recursive functions in a smart way to simulate what would be a variable and loop over the list in C#. For more details on this: https://fsharpforfunandprofit.com/posts/recursive-types-and-folds-2b/. With fold and map it is possible to make small functions and combine them together to provide the answer that is required. (In f# fold and map are implemented in many modules such as Seq, List and Option. Be sure to always check if the module has fold or map and prefer to use these functions over writing your own).  
What type providers can’t do
There are many other posts and videos on type providers but not a lot of details on their limitations. The first, and hopefully the most obvious case is that type providers can’t handle when the type of the data is changing at runtime. Since the types are checked at compile time, if they change at runtime then the application will crash with an exception. Not analysing enough of the data will cause this exception so make sure you have sufficient data, or find the schema of the data. The second is multiple sources with similar data, think multiple CSV files with slightly different columns. In some cases it’s possible to use multiple type providers over each different file and then join the results together. If that is not possible, then dropping down to standard way of handling the data would be the best (F# is still the best tool for doing this). For our CSV example, that would be using a CsvParser. The final case is with SQL data and managing migrations. Currently the recommended approach is to handle the migrations separately from the application (let me know if anyone has a better solution).
That’s it for now folks. Have fun using type providers and don’t forget to leave a comment on your success stories or failures.